Simplifying Kafka: Effortless Stream Processing with Docker
click here to read this in medium
Unlock the power of real-time data processing with Apache Kafka, and streamline your setup with Docker for an efficient, scalable solution.

Introduction to Apache Kafka
Imagine a river, endlessly flowing with data from countless sources. This is the world of streaming data, and navigating it requires a robust and efficient system. Enter Apache Kafka: a powerhouse designed to manage and process vast streams of real-time data. Kafka acts as an organizing force, ensuring every bit of data is processed systematically, maintaining order in the relentless stream of information.
Exploring Kafka, Zookeeper, and Fault Tolerance
To truly harness the capabilities of Kafka, along with its components like Zookeeper and its fault tolerance mechanisms, it’s essential to delve into the core concepts and functionalities that make Kafka a critical tool in data streaming and processing. More info on this topic this.
The Role of Kafka as Storage
The question arises: beyond its primary role, can Kafka be utilized as a storage system? This exploration reveals Kafka’s capabilities beyond real-time data processing. More info on this topic here.
Key Terminology in Kafka
Familiarizing yourself with Kafka’s terminology is crucial for navigating its ecosystem:
- Topic: A specific channel where data flows, categorized under a feed name.
- Partition: A segment within a topic for scalability, allowing parallel data consumption.
- Replica: Partition clones for fault tolerance, ensuring data availability.
- Producer: Applications that send data to Kafka, deciding on the partition for each record.
- Consumer: Applications that read and process the data stream from topics.
- Consumer Group: A collection of consumers sharing an identifier to divide processing workload.
- Broker: The heart of the Kafka cluster, managing data storage and communication.
- Zookeeper: Coordinates Kafka’s brokers, managing configuration and synchronization.
- Offset: A unique identifier for each record within a partition.
- Leader and Followers: Designations within replicas for handling requests and ensuring data integrity.
Deploying Kafka with Docker
We leverage Confluent’s open-source Kafka images for a Docker-based approach, simplifying Kafka deployment and making stream processing power readily accessible.

Practical Kafka Deployment: Docker and Python
To provide a hands-on example, we’ve prepared a comprehensive setup including a Docker Compose file and Python scripts for message handling.
Explore Our GitHub Repository
Access the necessary files on our GitHub repository:
📦POC_Kafka_python
┣ 📂connectors
┣ 📜.gitattributes
┣ 📜LICENSE
┣ 📜README.md
┣ 📜conduktor.yml
┣ 📜consumer.py
┣ 📜docker-compose.yml
┗ 📜producer.py
- docker-compose.yml: Sets up the Confluent Kafka environment in Docker containers.
Python Scripts:
- Producer Script: Sends 100 messages per second to a Kafka topic, showcasing Kafka’s high-volume handling.
- Consumer Script: Receives and processes messages from the Kafka topic in real-time.
Getting Started
1.Clone the Repository: Access all files for a Docker-based Kafka deployment.
git clone https://github.com/propardhu/POC_Kafka_python.git
2. Launch Kafka with Docker Compose: Start the Kafka environment using.Docker Compose.
cd POC_Kafka_python
Now setup your username and password for the admin portal at conduktor.yml
CDK_ORGANIZATION_NAME: "python_demo_medium"
CDK_ADMIN_EMAIL: "admin@admin.io"
CDK_ADMIN_PASSWORD: "admin"
# in conduktor.yml
Now get the docker up and running
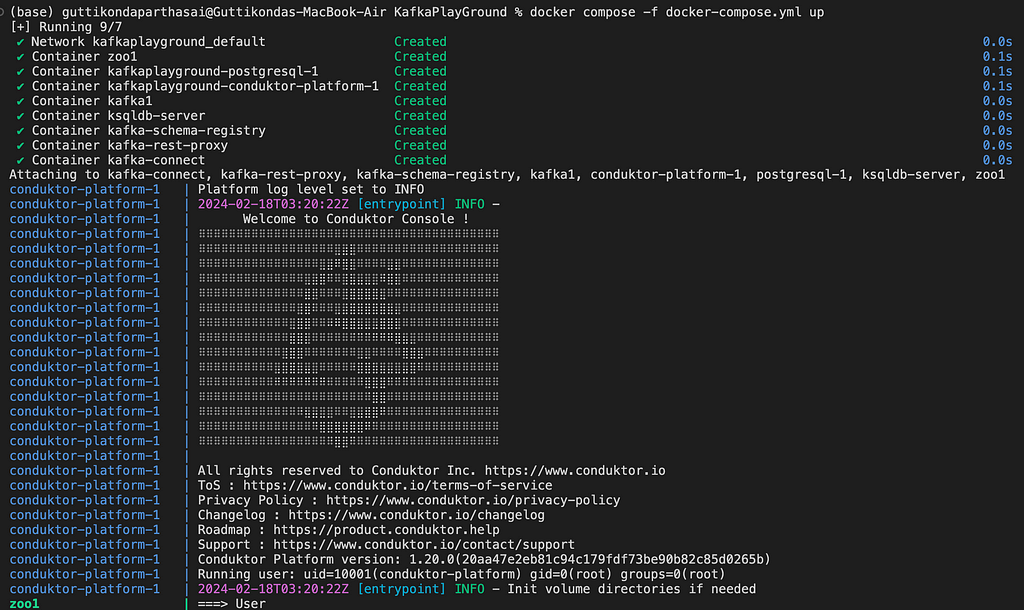
docker compose -f docker-compose.yml up
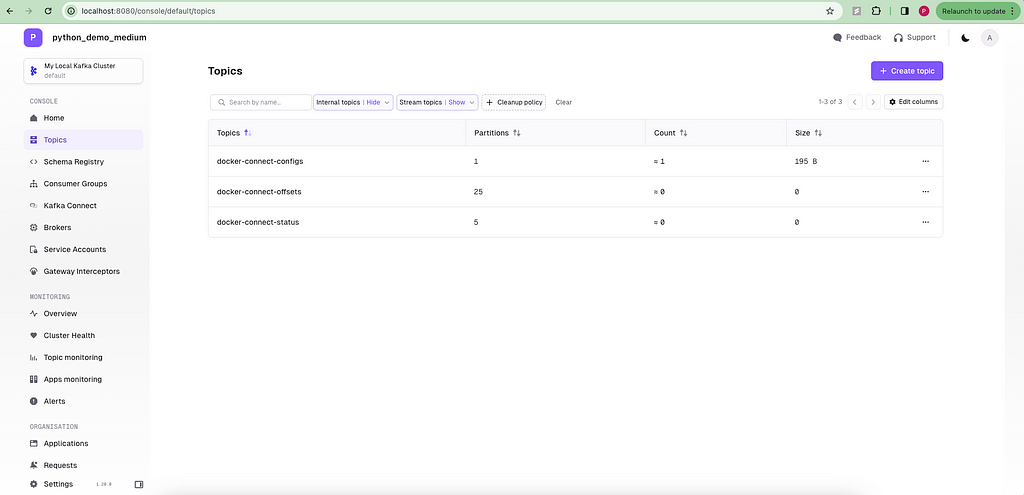
dashboard will be running at http://localhost:8080/
3.Execute the Python Scripts: Begin sending and receiving messages with Kafka by running the Python scripts.
run the two python file in two different terminals to see live streaming.
python producer.pyhttps://medium.com/media/08b30bbfe5eb7c9dfe4557793f4f0931/href
python consumer.py
This practical setup showcases Kafka’s capabilities within a Docker environment, emphasizing real-world applications of streaming data management.
What’s Next?
As we continue to explore the vast potential of Kafka, our journey into the world of stream processing and data handling is far from over. Stay tuned for our upcoming articles, where we will take a deeper dive into advanced integrations and applications of Kafka:
- Integrating Kafka with Spring Boot and Camel: Our next guides will delve into creating sophisticated messaging applications by leveraging Kafka with Spring Boot and Apache Camel. This integration will provide a powerful foundation for building robust, scalable applications that can process and route data efficiently.
- Harnessing Unsupervised Learning in Kafka Networks: Beyond traditional applications, we’re venturing into the cutting-edge territory of machine learning. We will explore how unsupervised learning algorithms can be integrated into the Kafka network. This initiative aims to uncover insights from the diverse kinds of data streaming through Kafka. By applying machine learning, we can automate the identification of patterns, anomalies, and trends within the data, enhancing the intelligence and adaptability of our systems.
These upcoming articles will not only expand your toolkit but also open new horizons for innovation within your Kafka deployments. Whether it’s through advanced application integrations or the pioneering application of machine learning, the goal is to unlock new levels of efficiency, insight, and functionality in your data streaming projects.
